

What is a Parallel Database?
As you probably know, cloud environments are made up of a very large number of independent processors that do a lot of things simultaneously, but not in parallel. Parallelism requires systematic coordination between processes to complete a specific task. In the case of databases, this means solving a single query in a parallel manner. Since performing JOINs is a key part of any relational query, the problem becomes: How do you design a database to perform a parallel query?
For a query to be parallel, the JOIN should be executed in parallel. But how is this achieved? In simplest terms, divide a table into portion so that a portion of one table joins with a single portion of another table. Each process accesses its portion of each table WITHOUT interference of or interfering with any other process acting on different portions of the same tables. Early versions of such systems were created using separate computer systems interfaced using a high-speed network. One system was the controller, that received and compiled SQL commands. The controller would then send tasks to each processor to complete. No resources are shared between processors. It processes its data as directed by the controller. This is referred to as a Shared-Nothing Architecture and is implemented as an MPP database.
The MPP Database
A Massive Parallel Processing (MPP) database is a hardware architecture made up of multiple independent systems (CPU, Memory, and Disk) often called a Data Slice, managed by a controller system. The controller handles all interactions with the outside world and orchestrates execution of the data slices. As forementioned, this is a shared nothing architecture. All interaction is through the controller.
Figure 1 below, shows a typical arrangement of an MPP with 5 data slices, numbered 0 through 4. The controller will receive a query, compile it, then send directions to each of the data slices to resolve the query. Each slice handles its part of the query without communicating with other data slices. The controller assembles the results and sends them to the user.
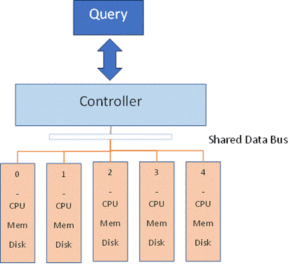
Performance is achieved using a technique called “co-location”. That is, distribute a table across the data slices based on its join key. When a row is inserted into such a table, the key column value is hashed (probably using a CRC) then divided by the number of data slices. The remainder from the division selects the data slice. The objective is to do it in such a way that distributes data evenly across the data slices and matches the distribution of an often used JOIN target.
How Co-Location Works
When you define the Table, you choose Columns that are used by the Database to decide which data slice to place the Row. When you INSERT a new Row, the system uses a deterministic algorithm to decide which data slice receives the Row. This becomes the permanent physical location of the Row. It can only be accessed by that processor in that data slice.
For the data distribution to be beneficial, you use column(s) that are used to JOIN with another Table. In the case of Star Schema, the common practice is to distribute Fact tables on the foreign key of its most populous Dimension. Dimensions are distributed on their primary key. Some MPP systems offered a DISTRIBUTE ALL option, that placed a full copy of the table in each data slice. This would only be used for small tables.
If you distribute two tables along the same key (co-locate) and JOIN them, the system can direct all the data slices to perform the join with the data they have. If you join 2 tables that are not distributed in the same manner, the controller will initiate a broadcast of the smaller table, causing each data slice to send the piece of the table it has to all the other data slices. Excessive broadcasts will cripple a poorly designed parallel schema.
Spark Parallel Databases
As Spark is a Symmetrical Multiprocessor System (SMP) and data access is shared, none of the commercially available databases are MPP databases. Instead, parallelism is achieved using table clustering, rather than table distribution.
Some databases use the term DISTRIBUTION, inheriting MPP terminology. Other databases use the term CLUSTER. In a Spark environment, these terms mean the same thing.
A cluster is defined in the same manner as distribution. You specify one or more columns as the cluster key. Like an MPP, the key is hashed, then divided by the number of clusters and the remainder chooses the cluster. When you join two tables on matching cluster keys, the system will fire off multiple processes to do the joins in parallel across each cluster pair. If the cluster arrangements do not match, it still executes parallel processes, but one of the tables needs to be joined in its entirety in each process. Unlike an MPP, data is not broadcast as Sparc is a shared environment. A non-clustered table is read directly by each process.
How Clustering Works
As an example, let’s say you have a Sales fact table and 2 dimensions: a customer dimension and a date dimension. The date dimension is small, so it is not clustered, while both customer and sales facts are clustered on CUSTOMER_KEY. It is a small system, so there are 5 clusters. Each cluster is a separate data object.
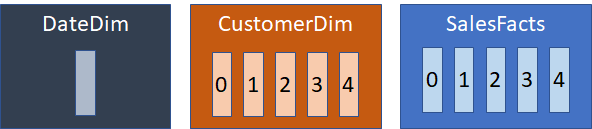
On disk, the Date dimension is stored in a single data object, while both the customer dimension and sales facts are spread across 5 data objects, numbered 0 thru 4 representing the remainder from the distribution process. Since the latter two tables are both clustered on CUSTOMER_KEY, related data is stored in the same numbered data object. When queried, the system will execute 5 processes in parallel, each doing a portion of the joins using data in the appropriate cluster.
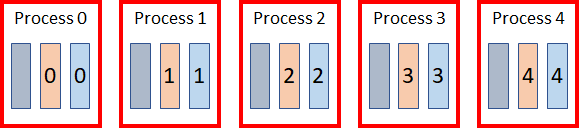
As the Date dimension is not clustered, it is used in all five processes. For the others, the fact and dimension join only uses the matching clusters, allowing each JOIN to work with 20% of the data.
Effect on Star Schema Queries
At this point it should be clear to you that this approach is only helpful for one join in the query. Since most queries involve more than two tables, how is this approach better? If you are implementing a normalized data structure, it isn’t. The only things that can be effectively clustered are subordinate table pairs, such as an order header table and an order line table. Performance of additional joins in the query can be dismal. MPP database systems that supported a normalized model strategy also supported a vast array of indexing structures in an attempt to achieve fast query times. Such systems required regular maintenance and tinkering to address user query performance issues.
A Star Schema, on the other hand, performs extremely well with this architecture due to the nature of the table structures:
- Surrogate keys ensure all joins must be equijoins.
- Most Dimension tables are relatively small.
- Fact tables are significantly larger than Dimension tables.
Next, it is important to understand optimizations the query compiler will perform when given a query against a Star Schema. The collection of equijoins from a central table clues the optimizer. It determines if one of the joins has a common cluster structure. If so, that join is performed last. The system then projects each of the other Dimension tables into cache. It then performs the final join in parallel, with a single pass through the Fact table taking the other Dimension attributes from cache. Under Sparc, this memory cache is shared, so it is a bit more efficient than the old MPP’s.
Also, another advantage of this approach is you don’t need indexes. A majority of the JOINs are performed in memory against cached data and the one table that is joined is a fraction of its total size. All queries against properly clustered tables will always be optimal unless the Star has more than one very large dimension. In such a situation you need to make your best guess on which Dimension to distribute the Facts. In extreme cases you could manage multiple copies of the Fact table with different distributions, but I haven’t seen such a case that needed such a solution.
Commercial Implementations
In almost all implementations, the number of clusters for a table is fixed, based on your configuration. This determines the level of parallelization attainable in your database. It is common for this to be different across environments. Usually, development is the smallest. In general, the QA and production environments are usually the same so that performance issues can be discovered and resolved before promoting a release to production. When moving tables between environments you should rebuild them, using CTAS so the rows are distributed in the same manner as other tables in the environment. Clustering mismatches will result in serial execution of a query.
In all cases, the system determines if it can perform a parallel join prior to executing it. It does so based on the following criteria:
- There is an equijoin between two tables (i.e. keya = keyb)
- All distribution columns are used in the JOIN
- The tables are distributed on the same columns
Since you must use all distribution columns between the two tables in the JOIN, common practice is to only declare one such column. In a star schema, large Dimension tables are clustered on the surrogate primary key. Small Dimensions (100MB or so) are not clustered. Fact tables are clustered on the foreign key of the most populous Dimension in a Fact table.
Redshift
Redshift syntax uses the term DISTKEY, for ‘distribution key’. It allows you to choose one column in the table to serve that purpose.
Snowflake
Snowflake uses the CLUSTER BY clause. It allows you to list multiple columns.
Databricks
Databricks uses CLUSTERED BY. It allows you to list multiple columns. Databricks allows you to partition a table as well.
Databricks also requires you to specify the number of clusters (BUCKETS). When doing so, the number of clusters should be the same or an integer multiple of the other. This is because it uses the remainder to choose the bucket. If you use an integer multiple, it can pair clusters that have compatible remainders. Otherwise, it will not perform a parallel JOIN.
Big Query
Big Query uses CLUSTER BY. It allows you to list multiple columns and also supports partitioning.
Azure Synapse
Synapse uses DISTRIBUTION = HASH(column names…) syntax. It also supports partitioning.
Other Options
Besides distributing on a column value, most allow you to specify a ROUND-ROBIN or ALL distribution. ROUND-ROBIN means the data is distributed evenly across all clusters. As no distribution column is specified, the system cannot use a parallel join, as any row could be in any cluster. This is normally used for tables that are not JOINed, such as staging or interim tables. The ALL option, on an MPP, meant that a full copy of the table exists in each data slice. In Spark, it means the table is not distributed.
Partitioning
Some databases allow for table partitioning as well. Partitioning allows a query to deal with less data if a query filters on the partition criteria. When partitioning is used, it is almost always based on Date. This allows a database to retain a lot of history without impacting most queries.
You need to be careful when combining partitioning with clustering. You do not want to create too many data objects for a table. If each object is too small, the system will be spending most of its time opening each object, rather than reading data. This can have a very severe impact on query times, defeating the purpose of parallel execution.
Indexing
If you are implementing Star Schema, I do not recommend indexing of any sort. Indexing introduces significant overhead when loading data. They also require regular maintenance to ensure performance. Also, typical analytic queries often access most rows. Using an index, queries will only run faster than a full table scan if it uses less than 5% of the rows in the table.
If performance is a problem, you are usually better off increasing the number of clusters rather than implementing indexes.
Your Vendor
There are various ways a vendor may provide services to such databases. Foremost is the size of the configuration. In addition, physical attributes such as solid-state disk, dedicated cores, storage proximity, and other features may be available.
It is normal that the development environment is small. However, I would recommend identical configurations for QA and Production. This provides a means to identify performance issues before release.
Data Integration – Effect of Clustering Differences
If you are doing a wholesale integration of many external databases, common practice is to replicate or copy the data objects. When you do this using non-database utilities, the table maintains the same cluster structure as the original database. This also occurs when copying tables between environments (Dev to QA for example).
When you join these tables with native tables, the cluster mismatch forces the system to treat them as two non-clustered tables. This will significantly degrade performance.
To resolve this, you must use the DBMS to physically copy (CTAS) each table before you use them in the new environment. This will redistribute the data to the native cluster arrangement.
Effect of Data Skew
Data skew refers to the difference between the number of rows in a particular cluster versus the average number of rows per cluster.
Skew hurts parallel queries because the shortest completion time is based on the biggest (slowest) cluster. Each parallel process must complete for the query to finish. Ideally, skew should be kept to within +/-5% of average. A skew of 10% or more is considered a worst-case scenario and should be addressed.
This is a significant problem in some industries. In Retail, over 40% of transactions are anonymous. These cash transactions are a disaster to tables clustered around Customer. This can be resolved by creating multiple, randomly chosen, anonymous customer identifiers. Such as “CUST001” through “CUST999” to spread the data evenly among the clusters. The chosen range should be 3 to 5 times the number of clusters to ensure an even distribution. The number of random values should be an even multiple of the number of clusters. An uneven multiple will cause skewed distribution.
Effect of Column Oriented Structures
A number of vendors tout their use of column-oriented Tables and is often mis-construed as the reason for a Parallel Database’s performance. That is a misstatement.
Tables stored using column-oriented structures provide a number of advantages to queries:
- Only reads data of the columns the query projects.
- Ability to quickly isolate populations based on attribute filters.
In such tables, when you read a “row”, the actual data value is retrieved based in handles stored in the database. This redirection and data compression adds a lot of processor effort to materializing the row. It gains the advantage in that it only needs to materialize specific columns, allowing it to cache and reduce the amount of work, including I/O, which can reduce query times by 20% or more,
As much as column-oriented structures can improve performance, it is Parallelism that provides orders of magnitude reduction in query times. Parallelism is always the primary avenue for optimization.
Summary
Here is a list of databases reviewed and how they implemented parallelism:
| Database | Syntax | Partitions |
|---|---|---|
| Redshift | MPP | No |
| Snowflake | Cluster | No |
| Azure Synapse | MPP | Yes |
| Databricks | Cluster | Yes |
| Big Query | Cluster | Yes |
MPP syntax means it uses the DISTRIBUTE ON clause in CREATE TABLE DDL. Others use CLUSTER. Note that the lack of partitioning is usually not an issue unless you are dealing with VERY large volumes of data and queries use filters to take advantage of it. Exceedingly large volumes can often be better addressed by increasing the number of clusters.
Design Tips
- Don’t define clusters if you do not need to. Dimension tables under100MB are usually too small to cluster. They will usually be cached and not have a material impact on query times. Only cluster your largest dimensions.
- Define a cluster using as few columns as possible. Ideally one column. If you use multiple columns, ALL columns MUST be used in the JOIN because the remainder is calculated by a hash of all the columns. Without the full join condition, it cannot pair clusters and perform the query in parallel.
- Never distribute a Fact table on more than one foreign key.
- Choose a cluster key that spreads the data evenly among clusters. As a rule, cluster size variance should be within +-5% of the average size.
- In a Star Schema, cluster dimensions on their primary key and fact tables on the dimension foreign key with the highest cardinality. This ensures colocation for the largest join and improves the chance for an even distribution.
Leave a Reply
You must be logged in to post a comment.