
Other Cloud Parallel Databases
In my earlier blog I discussed MPP style cloud databases. These databases imitate a physical MPP system on conventional hardware. An MPP requires very specific thoughts on how to arrange the data, so queries run efficiently. But almost all other databases claim they can handle huge amounts of data without ANY preparation.
What gives?
Busy Bees
The first database system available in the cloud was Hive who had an elephant partner named Hadoop. Hadoop handles data access. It would use a framework called Map-Reduce to handle data manipulation.
In this framework you have two functions: Map and Reduce. The Map function gathers data, and the Reduce function does something with it. Data is handled by Hive and passed between them as Key-Value pairs.
How Map-Reduce Works
Assume we have two tables: Members and Interests. We want to create a list of all members and their interests.
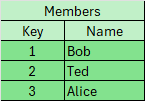
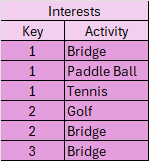
The query would be:
SELECT m.Key, m.Name, i.Activity
FROM Members m, Interests i
WHERE m.Key = i.Key
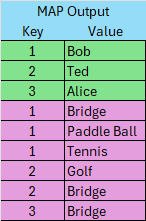
Step 1 – Map Gathers the Data and sends to Hive
Multiple instances of Map may execute reading different source tables. Map creates individual key/value pair objects. The value portion is a JSON string (not shown for simplicity) and may contain multiple columns from the same row. These are sent to Hive.
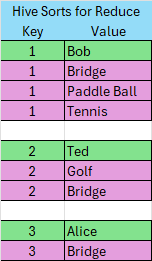
Step 2 – Hive sorts and groups the data on the Join key and sends to Reduce
This is the distribution part based on the Join key. No implicit distribution is declared for a Table. It creates individual objects by key. The value side is an array of rows with the same key. In this example, three objects are passed to Reduce.
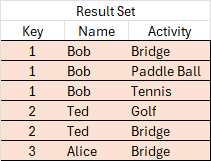
Step 3 – Reduce creates the Result Set
Reduce receives the data from Hive and creates the result set. In more complex queries, this set may go on for further processing.
Along comes Tez
Map-Reduce was sucessful and laid out how parallelism can be effected among a massive array of interconnected CPUs. While functional, it failed high-performance expectations with very large databases.
Apache Tez made a significant improvement on this by leveraging the large memory space to significantly reduce the amount of I/O imposed by Map-Reduce. It appears to take a comprehensive approach to the query rather than treat it as a series of individual joins.
Commercial Products
While the open-source history is clear, what is less clear is what vendors have done. It is reasonable to expect that they have their own ‘tweaks’ to improve functionality and performance. Legacy databases further widen the choices. So, take time to evaluate your options when choosing.
The cost of entry is exceptionally low, but the cost to change after years of development can be crippling. When you have selected a product, I recommend taking the time to perform worse-case performance tests with your data to verify your expectations. This need only take a short time and should comfirm the choice.
Conclusion
Any of these relational databases will support analytics or transactional needs for most organizations. However, if you need to support hundreds of analytics users against a vast database, you may want to consider an MPP. A professionally designed MPP schema will always outperform other databases.