
Understanding Cloud Parallel Databases
What is a Parallel Database?
As you probably know, cloud environments are made up of a very large number of independent processors that do a lot of things simultaneously, but not in parallel. A Parallel Database allows you to arrange the data so that a single query can be sub-divided across individual processors to perform joins with their own subset of data (some fraction of the table) independently of all other processors. In the past, this was addressed by MPP databases.
The MPP Database
A Massive Parallel Processing (MPP) database is a hardware architecture made up of multiple independent systems (CPU, Memory, and Disk) often called a data slice, managed by a controller system. The controller handles all interactions with the outside world and orchestrates the execution of the data slices. Of special note, this is a shared nothing architecture, meaning that each data slice executes on its own without any interaction with the other data slices.
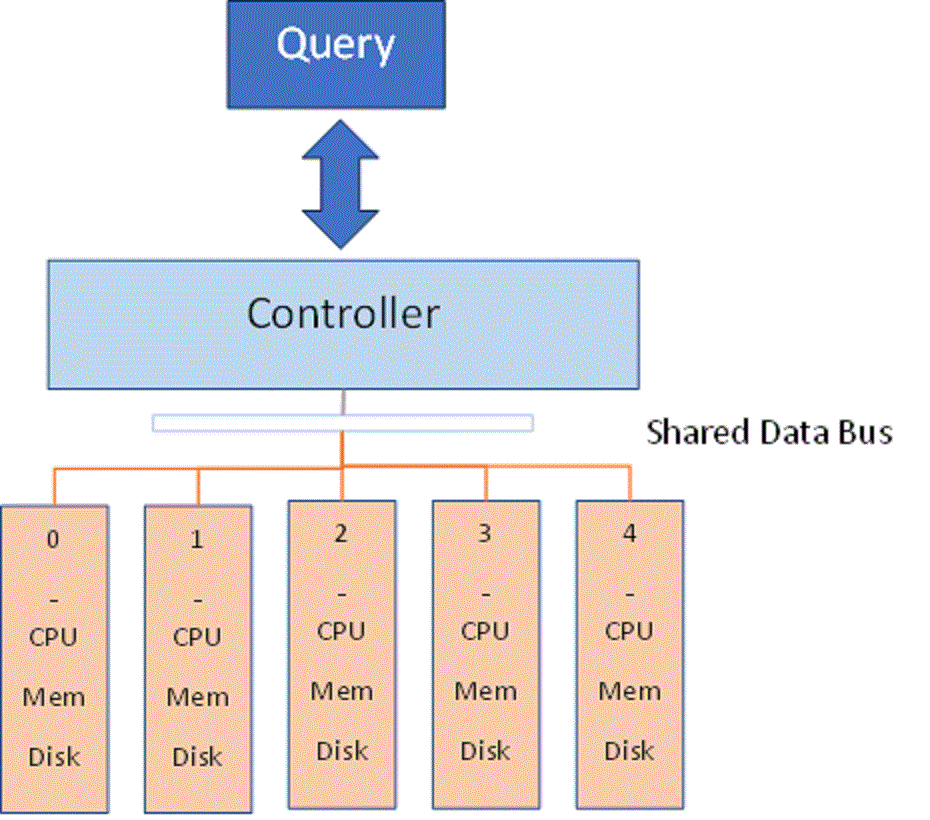
Fig 1 – A 5 processor MPP system
Above shows a typical arrangement of an MPP with 5 data slices, numbered 0 through 4. The controller will receive a query, compile it, then send directions to each of the data slices to resolve the query. Each slice handles its part of the query without communicating with other data slices. The controller assembles the results and sends them to the user.
Performance is achieved using a technique called “co-location”. That is, distribute a table across the data slices based on its join key. When a row is inserted into such a table, the key column value is hashed then divided by the number of data slices. The remainder from the division selects the data slice. The objective is to distribute data evenly across the data slices.
If you distribute two tables along the same key and JOIN them, the system can direct all the data slices to perform the join with the data they have. In theory, if you distribute the data across 20 sub-tables and join properly, the query should run a little less than 20 times faster. If you join 2 tables that are not distributed in the same manner, the controller will initiate a broadcast of the smaller table, causing each data slice to send the piece of the table it has to all the other data slices. Excessive broadcasts will cripple a poorly designed parallel schema.
Sparc Parallel Databases
As Sparc is a Symmetrical Multiprocessor System (SMP) and data access is shared, none of the commercially available databases are true MPP databases. Instead, parallelism is achieved by distributing the data across multiple sub-tables (a data slice), one for each distribution set.
Redshift is an example of a pseudo-MPP database. It retains the syntax of a classic MPP, such as Netezza, allowing someone to port such applications without significant code changes.
Distribution is defined by specifying one or more columns as the distribution key. Redshift only allows you to specify a single column, which is actually better as using multiple columns can cause problems. If you use multiple columns (some databases allow it) the combined (concatenated) value of all the columns is hashed to compute the remainder. For this to be useful, you must include all the columns in the JOIN expression. If you do not, it cannot perform a parallel join, significantly increasing query time. My own experience fixing bad designs has reduced multi-hour queries to a few minutes.
Databases that allow multiple columns do not have any ‘priority’ implied in the ordering of the columns. It does not allow you to use a ‘partial’ key as the entire key is needed to hash and calculate the data slice.
In a ‘true’ MPP, misusing distribution like this is a disaster waiting to happen. One table must be broadcast, and a full copy of the table is placed in each data slice before it can start the join. It is not as drastic in a cloud system as each data slice has full access to all tables in the database. So, it doesn’t need to move things around before it can join. But it is still unable to join in parallel.
How Distribution Works
As an example, let’s say you have a Sales fact table and 2 dimensions: a customer dimension and a date dimension. The date dimension is small, so it is not distributed, while both customer and sales facts are defined with 5 slices and distributed on CUSTOMER_KEY. Each slice is a separate data file, so each table would be stored as:
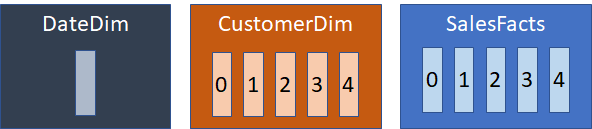
Figure 2 – Distributed and non-distributed tables
On disk, the Date dimension is stored in a single data file, while both the customer dimension and sales facts are spread across 5 data files. Since the latter two tables are both distributed on CUSTOMER_KEY, related data is stored in the same numbered data object. When queried, the system will execute 5 processes in parallel, each doing a portion of the joins using data in the appropriate slice.
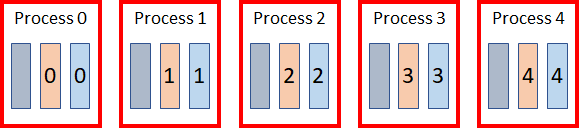
Figure 3- Parallel Query Execution
As the Date dimension is not distributed, it is used in all five processes. For the others, the fact and dimension join only uses the matching slices, allowing each join to work on 20% of the data.
These systems may be very large. Cloud vendors allow you to configure what you need. Having thousands of processors is not out of the question. The largest system I have delt with is a 2200+ processor Netezza system.
Designing an Optimal Schema
The optimal data schema for parallelization is a Star Schema. Normalized data models are very poor for such systems because all tables are based on a distinct unique primary key. Vendors that encouraged such modeling (Teradata) included an extensive array of bizarre indexing strategies to overcome the issue. So, the machine required a lot of handholding to get performance from it. Most of the parallel databases I am aware of do not support indexing, as 99% of the time it provides no benefit to large analytic queries. It also significantly slows down data loads.
A Star Schema works well because most of the time a schema has few large dimensions and a host of much smaller ones. If a dimension is under 20,000 rows or so, you usually do not define distribution. Everything goes into one slice. Bigger dimensions are distributed on the primary surrogate key. You then distribute the Fact table on the highest cardinality dimension foreign key. When such a table is queried, the system will first cache rows from the smaller dimensions, then make a single pass joining the Fact with the distributed dimension and incorporates the cached dimension data as it goes.
Joins are not a Problem
When I work with a client and suggest using star schema, I usually get resistance from developers complaining there are “too many joins” in a star schema, implying performance would be poor. So, I ask them to point me to a “flat” table they are using. I then analyze the data and break down the attributes and measures. Attributes are clumped into Dimension tables and the measures into a Fact table. I then run the same query against both data sets. When running on Redshift, the star query runs significantly faster than the flat table query and consumes at least 50% less resources to complete.
This difference is due to the column-oriented nature of the database. This method provides many advantages, reducing storage and improving query efficiency. But it cannot overcome a bad design. What column-oriented databases do is ‘tokenize’ column values, storing a small token instead of the full data value. This is accompanied by a cross-reference between the token and value.
In a flat table query, the system must translate the token to its data value every time it reads a row. If the table has a million rows, it does it a million times. However, in a star schema it reads much smaller Dimension tables, so it may only need to do the conversion a few thousand times.
The other reason a star schema is faster is the Dimensions are cached in memory, so the joins are essentially immediate.
This is makedly different than with a normalized data model. In a normalized data model, table joins are essentially a binary operation. Two sets are joined producing an intermediate set which is then joined with a third set and so on until the query is complete. As you can only distribute for one join, the query is best handled as a multi-step process with the intermediate set redistributed for the next join. This is essentially how Hadoop functions, redistributing the data as it goes along. Both of these situations results in multiple passes thru the data and constant redistribution.
Design Tips
- Define a distribution using as few columns as possible. Ideally only one column. If you use multiple columns, ALL columns MUST be used in the JOIN because the remainder is calculated by a hash of all the columns. Without the full join condition, it cannot pair slices and perform the query in parallel.
- Choose a distribution key that spreads the data evenly among slices. As a rule, the slice size variance should be within 5% of the average size. Too much data skew will slow performance which is bound by the largest slice. Sometimes you may need to ‘randomize’ a key, such as when loading cash customers in a retail setting. In such a situation, easily 30-40% of all rows will be placed in one data slice of a Fact table distributed on the Customer key.
- In a Star Schema, distribute dimensions on their primary key and fact tables on the dimension foreign key with the highest cardinality.